Available voices in Studio
Voices available in Studio differ in quality, control options, and stability.
At the moment, Studio supports the following voice tiers:
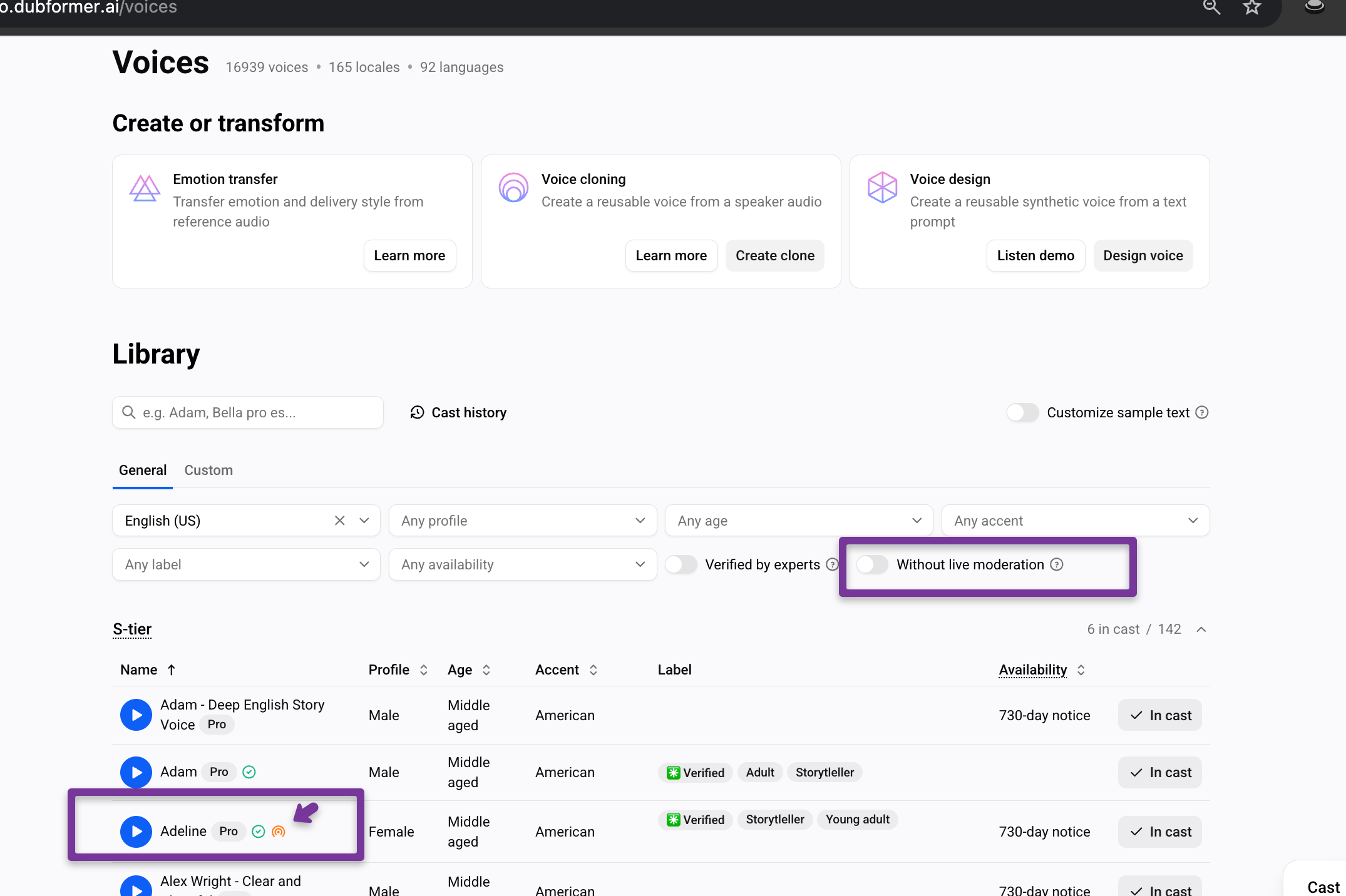
S-tier
A-tier
B-tier
C-tier
⚠️ Not all languages available in Studio support all voice tiers.
S-tier voices
S-tier voices use a new synthesis module
Pros
Highly natural, human-like sound
Strong intonation, pacing, and emotional nuance
Support for explicit reactions inside chunks, using brackets or tags for example:
[giggles],[sighs],[laughter]Find the supported reactions using the ‘Add tags’
Limitation
Doesn’t support pause breaks, for pauses, try bracketed pauses [long pause] or …
Some voices would behave different when using tags
A-tier voices
Good balance of naturalness and clarity
Available across multiple locales
(for example, EN-US–based English, LATAM-based Spanish)Support custom emotions and prompts to improve expressiveness
(results may vary)Support pause breaks for more natural pacing
Limitation
Doesn’t support brackets, tags (bracketed emotions, reaction, pauses)
B-tier voices
More synthetic and monotone compared to higher tiers
Do not support prompts or custom emotions
Do not support version-based synthesis
Support phonemes
Support pauses for pacing control
C-tier voices
Most synthetic and monotone tier
Do not support prompts or custom emotions
Do not support version-based synthesis
Support phonemes
Support pauses for pacing control
Moderated voices
Some S- tier and A-tier voices in Studio are marked with the Moderated voice tag.
This means that all text synthesized with this voice is checked in real time against a list of prohibited topics and words (e.g “suicide“, “violence“, etc)
This moderation is applied at the request of the voice talent who provided the voice.
If a chunk contains restricted words or topics, the chunk will not be synthesized.
What to expect
Moderation is applied automatically
The check happens during synthesis
Only the affected chunks are blocked
Other chunks in the task can still be processed
Models and methods
Studio relies on speech synthesis models provided by external vendors.
The exception is Emotion Transfer, which is a Dubformer-specific technology developed in-house and used to improve emotional expressiveness.